As a tech innovation company we have been structuring all of our internal processes in a way that would support iterative data-driven product development. Here is a quick summary of how we do it.
Structuring the Data Science process
We use Python as the core language or working with data. The analytics team uses Anaconda, an open-source Python and R distribution platform built for large-scale data processing and scientific computing. In addition, some of our team members also are experts in R. Data modelling and manipulation are done with Jupyter iPython and then shared with the engineers for implementation.
For version control we use GitHub, both within the Data Science team and when cooperating with our developers.
Process management
Each day, we run a standup meeting with a member of the Data team, the product owner, developers, and marketing lead. The project assumptions and other work in progress data is stored in a shared space on Podio.com.
Hiring Data Scientists
As for any Data Science company, finding the best data talent is always high up on the agenda for us, so the Skein team works with the leading technical universities, organises events and attends conferences on the topics of machine learning, web data analytics and predictive modelling.
Data Science applications
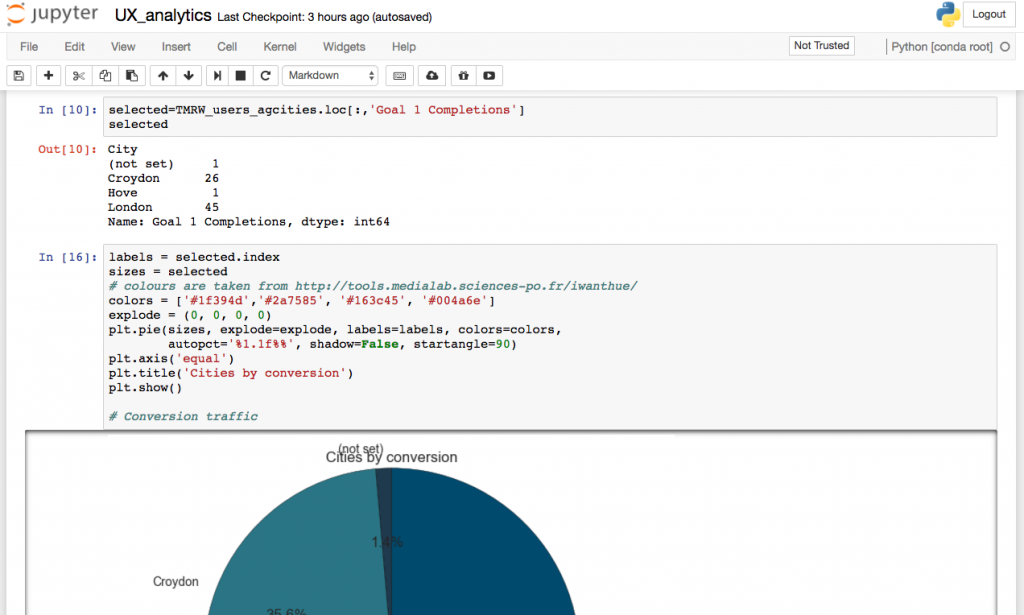
The projects we work on can roughly be split into categories of client projects, and internal tools as well as own user-facing projects. The most recent products we released are UX Data Analytics, a service that uses machine learning to provide insights on user experience and design improvement insights.

Big data visualisation
To communicate findings internally we use Python visualisation libraries and dashboards, and for external integration – front-end libraries such as JavaScript frameworks, including ReactJS and Angular.
Choosing the right way to present the findings and inspire actions is more art than science so as a guide we use a vast catalogue of visualisation tools and idea maps, such as the one below.

Image copyright: Anna Vital